
BLOG
Customer found defects – Everybody’s embarrassment, nobody’s fault
What’s the Deal with Customer Found Defects?
Driven by the goal to deliver high quality products to customers rapidly, engineering teams follow a systematic and disciplined approach to software development. It entails standardization of processes, increased automation, and adoption of best practices, across the application development and delivery lifecycle. Nevertheless, at the end of the day all of this effort seems worthless if your customers continue to report defects in the delivered software.
How did the defect go unnoticed, with such rigorous internal testing and quality checks? Where and when did it get introduced? Who or what is responsible? How long has it been there? What’s the impact? And finally, what will it take to fix it? While finding answers to these questions is complex and daunting, it seems crucial. Afterall, customer found defects (CFDs) can call into question your brand’s credibility and commitment to delivering quality and reliability rapidly.
What’s Beyond the ‘Known Knowns’?
As we diagnose the ‘what, when, and how’ of defects there are few fundamental questions that need to be answered. Are our quality assurance (QA) processes foolproof? What are we testing for? Are we missing out on tracking some known variables? Are there unknown variables in the equation which might catch us off guard? The Knowns and Unknowns framework of design thinking explains this really well.
“There are known knowns. These are things we know that we know. There are known unknowns. That is to say, there are things that we know we don’t know. But there are also unknown unknowns. There are things we don’t know we don’t know.” – DONALD RUMSFELD
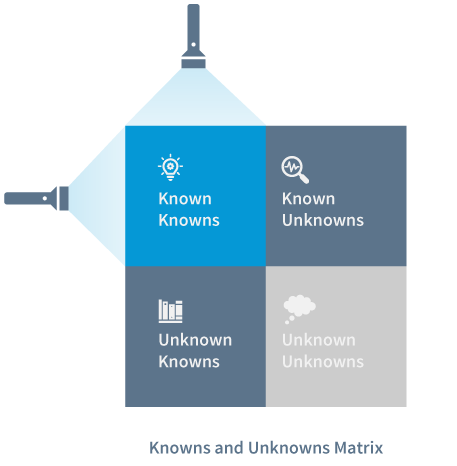
In most cases our QA processes are designed to track only the ‘Known Knowns’. These are predictable issues that have been encountered previously. There are several tests that ensure no such issues escape to the production environment – including unit tests, automated regression tests (ARTs), and even rigorous manual tests performed by specialized business analysts. As we perform tests, analyze data and define KPIs, we factor in these types of issues, defects, bugs, or errors. And it’s no surprise that we find only what we look for.
The second category is that of the ‘Known Unknowns’. It’s extremely difficult to get to the root cause of such issues, and as such it’s equally difficult to reproduce and test for such scenarios or predict their occurrence at an early stage. Giving in to the complexity of such scenarios, and the time-consuming process of diagnosing the cause of these issues, most QA teams knowingly skip testing for the ‘Known Unknowns’, introducing a certain amount of risk.
The third category termed as the ‘Unknown Knowns’ encompasses scenarios that we anticipate but can’t create in test environments. A system’s behavior or response to such scenarios isn’t predictable. For example, given the increased dependence on microservices and distributed cloud infrastructures, you can’t simulate the conditions of the production environment in the test environment to predict a system’s scalability or reliability. Nonetheless, engineering teams are adopting innovative approaches such as ‘Chaos Engineering’ to identify and address vulnerabilities in software, in the production environment.
The scenarios that fall in the fourth category – ‘Unknown Unknowns’, are the trickiest. These are issues that we are completely unaware of, and that pose unidentified risks. An apt analogy of such a scenario could be the ‘novel’ Coronavirus that led to a global pandemic that has taken the world by storm. As mankind battles this deadly virus that had never before been identified in humans, we need to rethink how we can be better prepared to deal with the ‘Unknown Unknowns’.
Maximize and Measure What’s ‘Known’ and Prepare for the ‘Unknown’
As quality and reliability engineering teams focus on implementing standard processes and best practices, they often ignore the most critical aspect to continually improving quality – measurement.
To begin with, you need to identify and standardize the key performance indicators (KPIs) to measure software quality throughout the development and delivery lifecycle. Having said that there’s no denying that measuring quality isn’t as simple as measuring time-to-market or other more tangible aspects of software delivery. It depends on a multitude of factors – some objective and some subjective. Defect metrics provide a quantitative approach to measuring software quality and effectiveness of the development and testing processes. For example, the ‘Defect Escape Ratio’ allows you to track what proportion of the defects in your software made it to the production stage, through development and QA. It represents CFDs as a percentage of the total number of defects – including internally found defects (IFDs) and CFDs.
Next, establish a baseline which allows you to perform a before-and-after analysis and track improvements. And finally, set achievable goals and define milestones. With this groundwork, you can continually track and measure the right metrics and iteratively improve software quality. However, this is applicable only to the ‘Known Knowns’ and in our endeavor to continually improve quality we need to keep decoding what’s unknown to maximize what’s known.
With greater visibility across all stages of application delivery, engineering teams can leverage advanced analytics and machine learning to diagnose the root cause of the ‘Known Unknowns’ and transition more and more issues to the ‘Known Knowns’ category.
Similarly, by extensive analysis of previously encountered failures – network, infrastructure, application, etc. – in the production environment, engineers can identify system vulnerabilities, assess potential risks, and take proactive measures to improve resilience against the ‘Unknown Knowns’.
Finally, real-time visibility into software performance with self-service analytics allows engineers to discover and fix any unanticipated issues at an early stage, enabling continuous reliability and thereby reducing the impact of the ‘Unknown Unknowns’.

Table of Contents
XOPS APPS BY GATHR
DevOps Apps
DORA++, DevOps360, & more
Boost your DevOps health and performance by simplifying application planning, development, delivery, and operations stages.
-
DORA++
-
DEVOPS 360
-
VULNERABILITY ANALYSIS
-
CONTINUOUS COMPLIANCE
-
DEVOPS TRACEABILITY
-
CI/CD PIPELINE MONITORING
-
CODE LEAK ANALYSIS
Recent Posts
View more postsBlog

Blog

Blog

Blog
